CORGi @ CMU

Computer Organization Research Group led by Prof. Nathan Beckmann
Navigate to
Funded by

Polymorphic Cache Hierarchy
Current systems hide data movement behind the load-store interface, and software’s lack of control over data movement is the root of many inefficiencies. To address this inefficiency, many have proposed specialized hardware. But specialized hardware is very expensive to design, verify, and build, and each new specialization is disruptive across the system stack.
We argue that the hardware-software interface is the actual problem, and specialized hardware is usually unnecessary. A Polymorphic Memory Hierarchy provides a much richer interface for data movement, letting software optimize data movement itself on general-purpose hardware. This project spans hardware, software, and compilers.
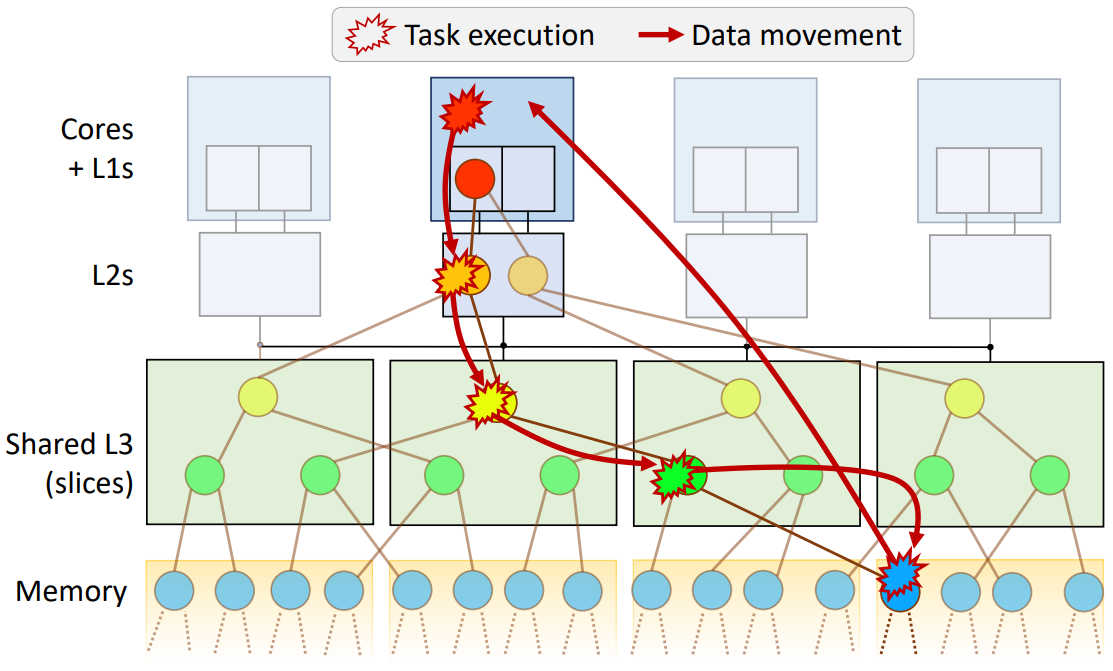
Livia was the first to enable data-centric computation throughout the memory hierarchy.
Livia accelerates task-parallel programs by migrating tasks and data to the location in the memory hierarchy
that minimizes overall data movement.
Livia programs are written using a continuation-passing API as a graph of dynamically generated tasks.
Tasks are written as functions following a standard signature,
and to launch a task programs simply invoke the appropriate function on the relevant data.
Livia hardware then automatically finds the data and executes the function nearby.
Functions can return values to the caller by fulfilling a future.
The above diagram shows how Livia executes a chain of tasks within the memory hierarchy. Livia hardware automatically migrates data to settle at its “natural” location in the memory hierarchy according to how its used, and then dynamically schedules task execution on the closest Memory Service Engine (see below) to maximize efficiency. Livia can improve performance by 2X on challenging irregular algorithms and data structures, which have proven difficult to accelerate.
täkō extends the programming interface to let software fully observe and control data movement. We observe that a key missing feature in current systems is software’s ability to observe and respond to data movement. täkō programs can register callbacks on certain address ranges so that software is invoked when data in this range moves. Specifically, täkō programs can register callbacks to execute on cache misses, evictions, or writebacks.
täkō enables optimizations in software that previously required specialized hardware, such as push-based cache semantics (PHI, MICRO’19) and decoupled graph traversals (HATS, MICRO’18). Further, täkō provides new capabilities beyond performance optimization (e.g., detecting cache side-channel attacks) by allowing software to monitor data movement.
Microarchitecturally, Polymorphic Cache Hierarchies distribute small “Memory Service Engines” (MSEs) on each tile of a multicore. These engines comprise hardware scheduling logic and a dataflow fabric that executes tasks efficiently. We are prototyping this design in RTL, including a detailed design of the dataflow fabric so that it can execute multiple concurrent tasks at low hardware overhead.
CORGi Members








Publications
Leviathan: A Unified System for General-Purpose Near-Data Computing [pdf]
Brian Schwedock, Nathan Beckmann. MICRO 2024.
Affinity Alloc: Taming Not-So-Near Data Computing [pdf]
Zhengrong Wang, Christopher Liu, Nathan Beckmann, Tony Nowatzki. MICRO 2023.
Kobold: Simplified Cache Coherence for Cache-Attached Accelerators [pdf]
Jennifer Brana, Brian Schwedock, Yatin Manerkar, Nathan Beckmann. IEEE CAL 2023.
Kobold: Simplified Cache Coherence for Cache-Attached Accelerators [pdf]
Jennifer Brana, Brian Schwedock, Yatin Manerkar, Nathan Beckmann. WDDSA at MICRO 2022.
täkō: A Polymorphic Cache Hierarchy for General-Purpose Optimization of Data Movement [pdf]
Brian Schwedock, Piratach Yoovidhya, Jennifer Seibert, Nathan Beckmann. ISCA 2022.
Tvarak: Software-Managed Hardware Offload for DAX NVM Storage Redundancy [pdf]
Rajat Kateja, Nathan Beckmann, Gregory R. Ganger. ISCA 2020.
Livia: Data-Centric Computing Throughout the Memory Hierarchy [pdf]
Elliot Lockerman, Axel Feldmann, Mohammad Bakhshalipour, Alexandru Stanescu, Shashwat Gupta, Daniel Sanchez, Nathan Beckmann. ASPLOS 2020.
PHI: Architectural Support for Synchronization- and Bandwidth-Efficient Commutative Scatter Updates [pdf]
Anurag Mukkara, Nathan Beckmann, Daniel Sanchez. MICRO 2019.
Improving the Locality of Graph Processing through Hardware-Accelerated Traversal Scheduling [pdf]
Anurag Mukkara, Nathan Beckmann, Maleen Abeydeera, Xiaosong Ma, Daniel Sanchez. MICRO 2018.
Cache-Guided Scheduling: Exploiting Caches to Maximize Locality in Graph Processing [pdf]
Anurag Mukkara, Nathan Beckmann, Daniel Sanchez. AGP at ISCA 2017.